CNNs for Computer Vision
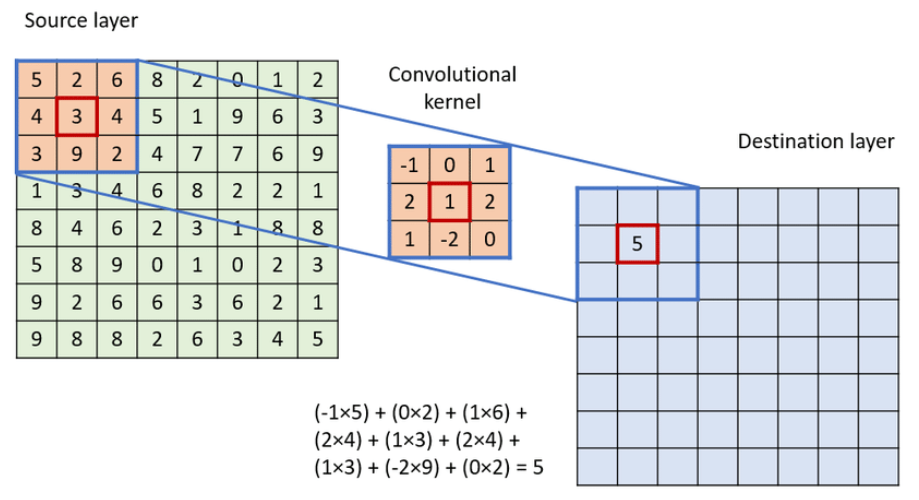
The Convolution operation
- A Kernel (Filter) slides over the input.
- Performs element-wise multiplication and sum.
- Produces a Feature Map.
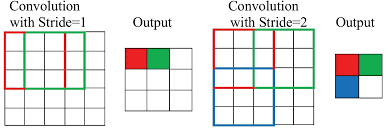
Hyperparameter: Stride
Stride controls how the filter moves:
- Stride = 1: Filter moves 1 pixel at a time.
- Stride = 2: Filter jumps 2 pixels (downsamples the image).
Higher stride reduces the spatial dimension of the output.
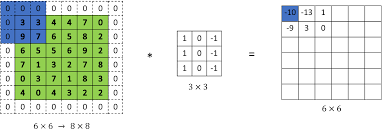
Hyperparameter: Padding
Convolutions shrink the image size. To maintain dimensions, we use Padding.
- Valid Padding: No padding (image shrinks).
- Same Padding: Zero-padding around edges so Output Size = Input Size.
Calculating Output Dimensions
Given input $W$, filter size $F$, stride $S$, and padding $P$, the output size is:
$$ Output = \lfloor \frac{W - F + 2P}{S} \rfloor + 1 $$
Question
$$ Output = \lfloor \frac{W - F + 2P}{S} \rfloor + 1 $$
Input: 5x5 image
Filter: 3x3
Stride: 1
Padding: 0
Formula: $(5 - 3 + 0)/1 + 1$
Output: 3x3 Feature Map
Pooling Layers
Pooling reduces dimensions to reduce parameters and computation.
- Max Pooling: Takes the maximum value in a window (most common).
- Average Pooling: Takes the average value.
Pooling provides translation invariance (small shifts don't change the max).

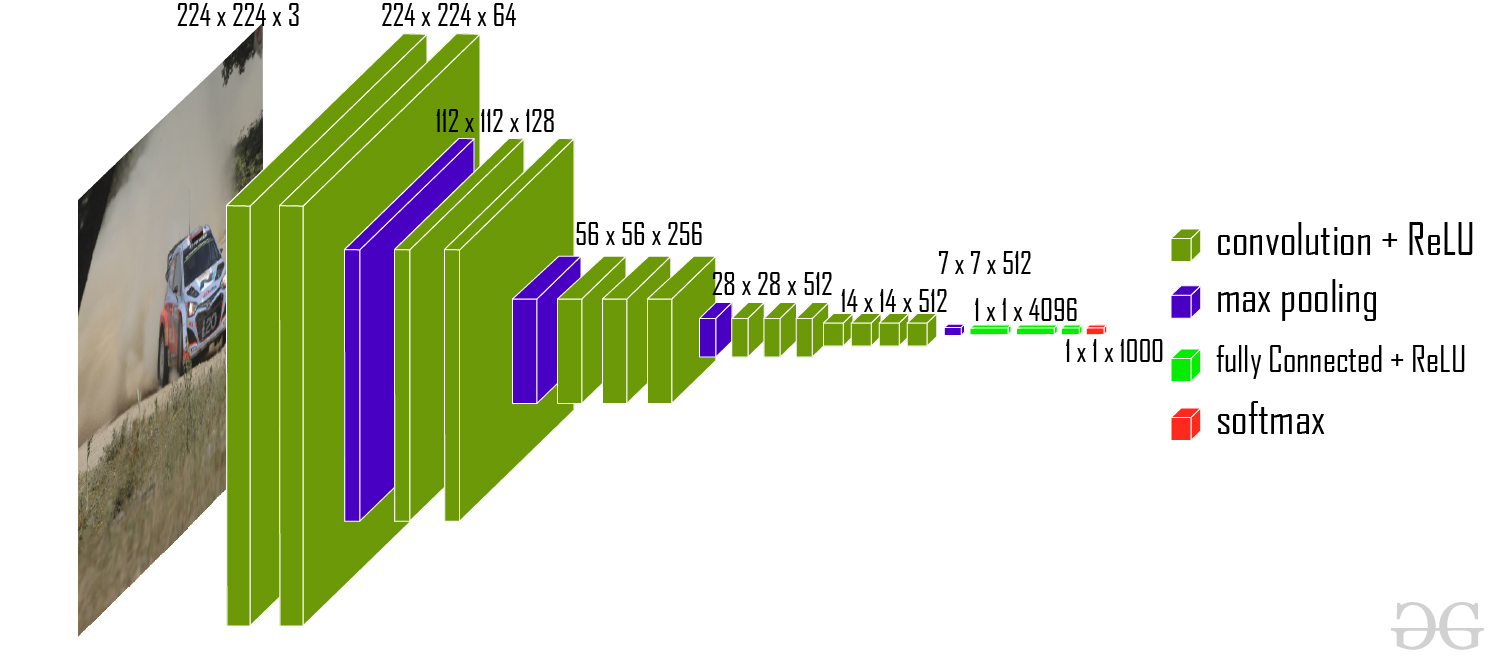
Classic Architecture: VGG16
- Uses only 3x3 convolutions stacked on top of each other.
- Very deep (16 layers).
- Concept: Small filters stacked deeply > One large filter.
The Problem with Depth
Why not just stack 100 layers?
Degradation Problem: As networks get deeper, accuracy gets worse (not just due to overfitting, but optimization difficulties).
Gradients vanish as they travel back through many layers.
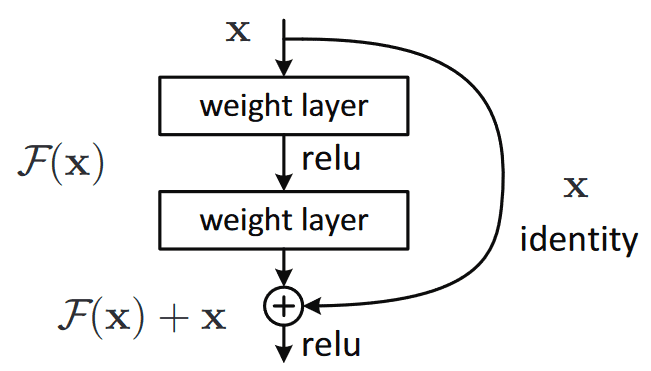
Solution: Residual Networks (ResNet)
Introduced Skip Connections (or Shortcut Connections).
- The input $x$ is added to the output of the layer: $F(x) + x$.
- Allows gradients to flow directly through the network.
Transfer Learning
Rarely in production should you train from scratch.
- Take a network trained on a huge dataset (e.g., ImageNet).
- Freeze the early layers (feature extractors).
- Replace the final classification layer.
- Train only the new layer on your small dataset.
Data Augmentation
What if you don't have enough data?
Fabricate it.
Data Augmentation
What if you don't have enough data?
Fabricate it.
- Random Rotations
- Flips (Horizontal/Vertical)
- Color Jitter (Brightness/Contrast)
- Zoom/Crop
Makes the model robust to variations.
Sequence Models
Handling Time, Text, and Audio.
The Limitation of Feedforward Networks
Standard networks (MLPs/CNNs) expect a fixed input size.
But real life is sequential:
- Text sentences (variable length)
- Audio signals
- Stock prices
Recurrent Neural Networks (RNNs)
RNNs process data one step at a time, maintaining an internal Hidden State.
$$ h_t = \tanh(W_x x_t + W_h h_{t-1} + b) $$
The state $h_t$ acts as the "memory" of the network.
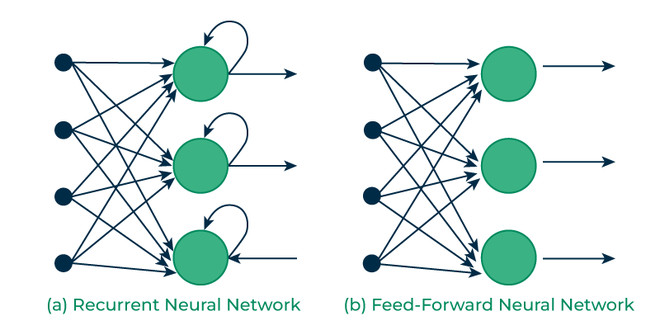
Unrolling the RNN
We can visualize an RNN by "unrolling" it across time steps.
- Same weights ($W_x, W_h$) are shared across all time steps.
- Allows processing of arbitrary sequence lengths.
Problem: Vanishing Gradient in Time
When training via Backpropagation Through Time (BPTT):
Gradients must flow from the last time step to the first.
- If the sequence is long, gradients are multiplied many times.
- Gradients $\to 0$. The network forgets early inputs.
Solution: LSTM (Long Short-Term Memory)
LSTMs introduce a separate Cell State ($C_t$) that runs straight down the entire chain with only minor linear interactions.
It acts as a conveyor belt for information.
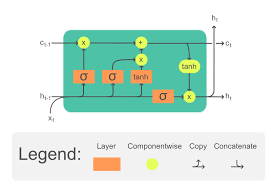
LSTM Gates
LSTMs use gates (sigmoid functions) to control information flow:
- Forget Gate: What info to throw away from cell state?
- Input Gate: What new info to store in cell state?
- Output Gate: What to output based on cell state?
GRU (Gated Recurrent Unit)
A simplified version of LSTM.
- Combines Forget and Input gates into an "Update Gate".
- Computationally cheaper, often performs just as well.
Applications of Sequence Models
- One-to-Many: Image Captioning (Image $\to$ Text)
- Many-to-One: Sentiment Analysis (Text $\to$ Rating)
- Many-to-Many: Machine Translation (English $\to$ French)
Transformers
Current State-of-the-Art
The Problem with RNNs
- Sequential computation: Cannot parallelize training. (Slow!)
- Long-term memory: Even LSTMs struggle with very long contexts (e.g., thousands of words).
Question: How can we look at the whole sentence at once?
Attention is All You Need (2017)
Google researchers proposed the Transformer architecture.
Key idea: Throw away recurrence. Use Self-Attention.
"The animal didn't cross the street because it was too wide."
Self-attention helps the model understand "it" refers to "street", not "animal".
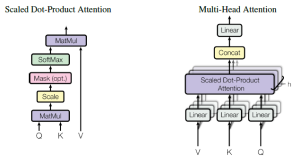
Self-Attention Mechanism
Every word attends to every other word. For each token, we generate three vectors:
- Query (Q): What am I looking for?
- Key (K): What do I contain?
- Value (V): What information do I pass along?
The Attention Formula
A "soft dictionary lookup":
$$ \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V $$
- $QK^T$: Similarity between Query and Key.
- Softmax: Normalizes scores to probabilities.
- $V$: Weighted sum of values.
Multi-Head Attention
Why have one attention mechanism when you can have many?
- Multiple "heads" run in parallel.
- One head might focus on grammar.
- Another might focus on semantic relationships.
- Another might focus on rhyme or tone.
Positional Encoding
Since Transformers process all words in parallel, they have no concept of "order".
We must add Positional Encodings (vectors representing position 1, 2, 3...) to the input embeddings so the model knows the word order.
The Transformer Block
A standard block consists of:
- Multi-Head Attention
- Add & Norm (Residual connection + Normalization)
- Feed Forward Network
- Add & Norm
![]()
The Transformer Block
A standard block consists of:
- Multi-Head Attention
- Add & Norm (Residual connection + Normalization)
- Feed Forward Network
- Add & Norm
![]()
Encoders vs Decoders
Encoder (e.g., BERT): Looks at the whole sentence (bidirectional). Good for understanding, classification, sentiment.
Decoder (e.g., GPT): Looks only at past words (autoregressive). Good for generation (predicting the next word).
Tokenization
Neural networks don't read text; they read numbers.
- Tokens: Words or sub-words.
- "The cat sat" $\to$ [101, 582, 993]
- Modern tokenizers (Byte-Pair Encoding) break down rare words into chunks.
Why Tokenization?
- Neural networks operate on vectors, not characters or words.
- Directly mapping every word → integer would require:
- A huge vocabulary (millions of words).
- No way to handle misspellings or unseen terms.
- Solution: Subword tokenization, balancing:
- Expressiveness
- Vocabulary size
- Robustness to unseen text
Tokenization Approaches
- Character-level
- Tiny vocab, but very long sequences.
- Word-level
- Simple, but huge vocab & poor handling of rare words.
- Subword-level (BPE / Unigram)
- Modern standard.
- Keeps common words intact.
- Splits rare or complex words into chunks.
- Examples:
- "unbelievable" →
["un", "believable"] - "electroencephalography" → many fragments
- "unbelievable" →
How Byte-Pair Encoding (BPE) Works
- Start with a vocabulary of single characters.
- Count all adjacent character pairs.
- Merge the most frequent pair (e.g., "th").
- Repeat tens of thousands of times.
- End result:
- Whole common words
- Useful subwords
- Short fragments for rare words
BPE Example Breakdown
- The string
"tokenization"might tokenize into:["token", "ization"]- or
["tok", "en", "ization"]
- The exact split depends on the model's learned merge rules.
- Common patterns → long tokens
- Rare patterns → short fragments
Tokenization Artefacts
- BPE is frequency-driven, so weird patterns appear:
"solidgoldmagikarp"→ single token- Space often merges with common words (e.g.,
" the") - Dataset effects:
- High-frequency internet slang → stable tokens ("lol")
- Scientific vocabulary → often fragmented
- These quirks influence model behaviour and reasoning.
Why Tokenization Matters for Costs
- Models bill per token, not per word.
- Different languages produce different token counts:
- English: few tokens/word
- German/Finnish: compounds → many tokens
- Chinese/Japanese: ~1 char = 1 token
- Long variable names, emojis, punctuation all inflate token usage.
Tokenization Affects Reasoning
- Models reason over token sequences, not words.
- If a word becomes many fragments, the concept becomes “longer” for the model:
- "neutrino" → multiple small tokens
- "dog" → typically a single token
- Consequences:
- Misspellings break reasoning paths
- Long numbers are hard (many tokens)
- Non-Latin languages degrade in small models
BERT (Bidirectional Encoder Representations)
- Masked Language Modeling: Hide 15% of words and ask the model to guess them.
- "The [MASK] sat on the mat."
- Allows the model to learn context from both left and right directions.
GPT (Generative Pre-trained Transformer)
- Causal Language Modeling: Predict the next token based only on previous tokens.
- Trained on massive amounts of internet text.
- Few-shot learner: Can perform tasks with minimal examples.
Generative AI
Creating new data rather than classifying old data.
Discriminative vs Generative
- Discriminative: $P(Y|X)$ - Given an image, is it a cat or dog?
- Generative: $P(X)$ - Generate a plausible image of a cat.
Autoencoders
Unsupervised learning method.
- Encoder: Compresses input into a small "Latent Space" (Bottleneck).
- Decoder: Reconstructs input from the latent vector.
Forces network to learn efficient data representation.
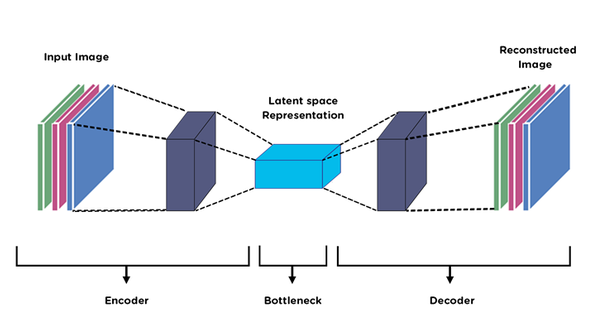
Latent Space
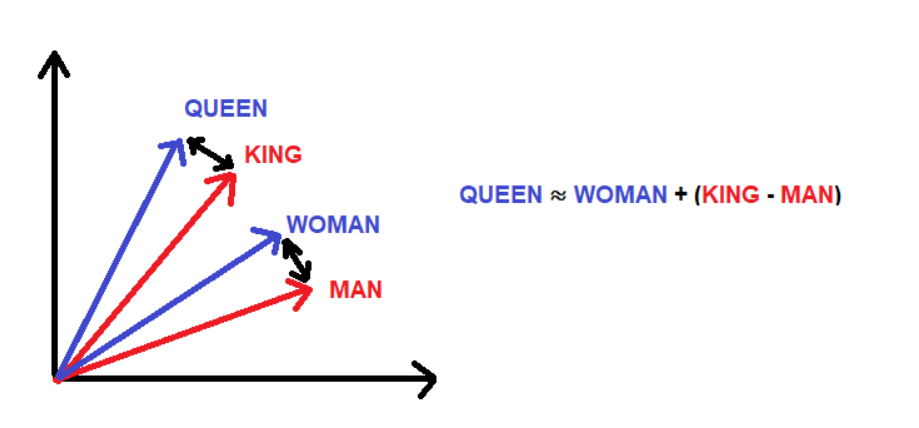
The "Bottleneck" is not just compression; it's a map of concepts.
- Nearby points in latent space $\to$ similar output images.
- "King" - "Man" + "Woman" = "Queen" (Vector arithmetic).
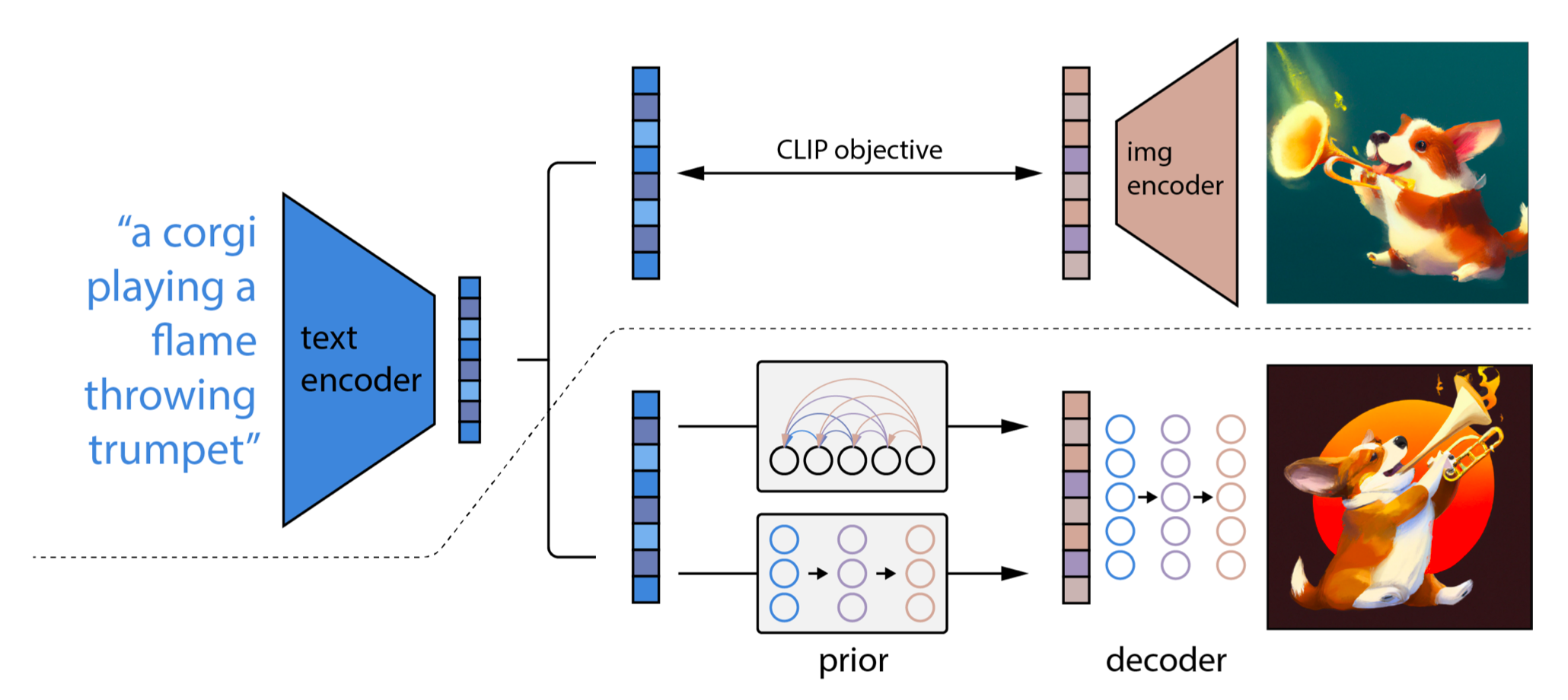
Diffusion Models (The Modern Era)
Used by DALL-E, Stable Diffusion, MidJourney.
Idea: Slowly destroy an image by adding noise until it is random static. Then, learn to reverse the process.
Diffusion: Forward vs Reverse
- Forward Process: Easy. Just add Gaussian noise.
- Reverse Process: Hard. Train a U-Net (neural network) to predict the noise added at each step and subtract it.
Text-to-Image Conditioning
How do we control what image is generated?
- We inject Text Embeddings (from a Transformer like CLIP) into the diffusion process.
- The noise subtraction is guided by the text prompt.
Reinforcement Learning
Learning by trial and error.
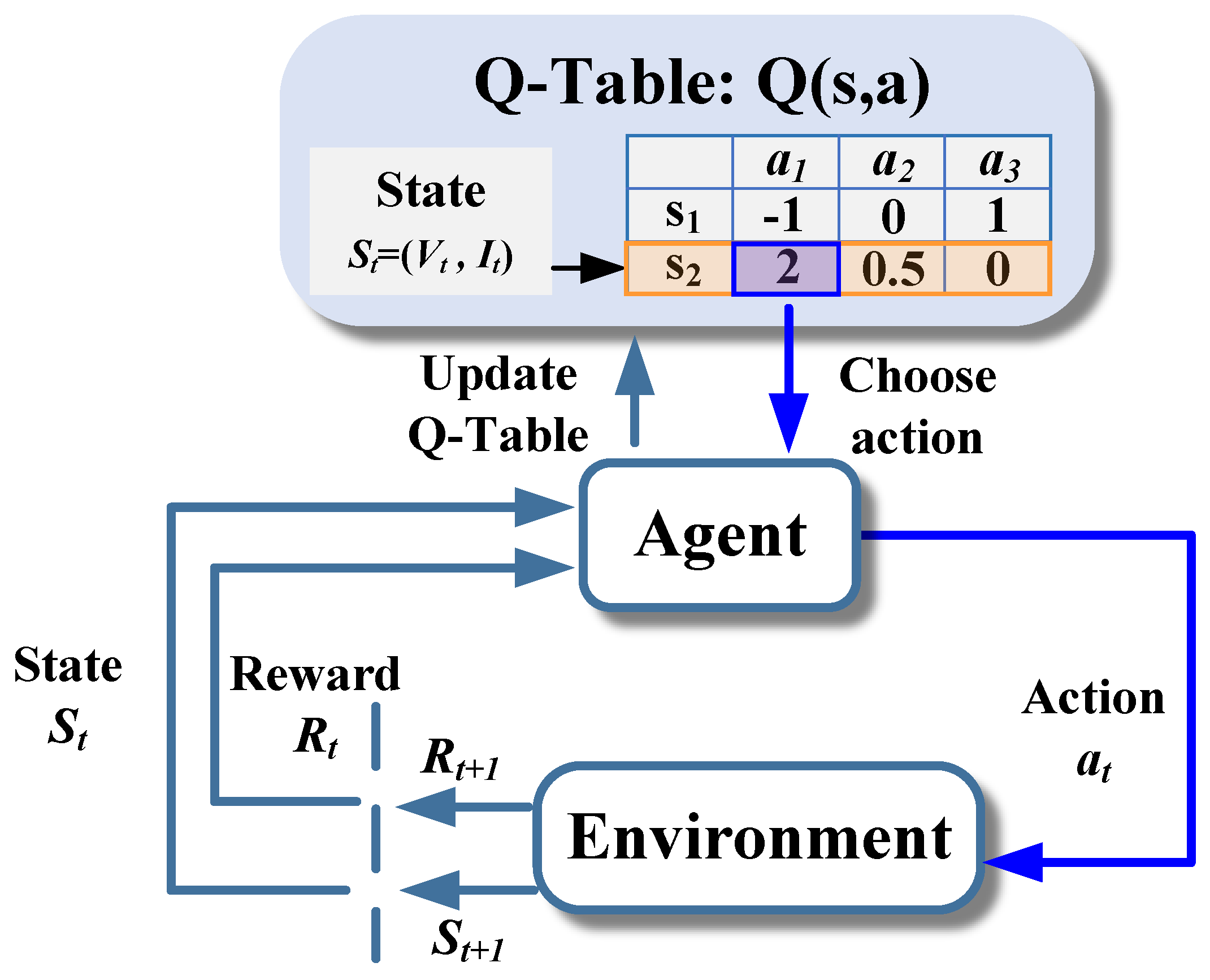
The RL Loop
- Agent: The learner (Neural Net).
- Environment: The world (Game, Robot sim).
- Action ($a$): What the agent does.
- State ($s$): Current situation.
- Reward ($r$): Feedback (+1 for goal, -1 for crash).
Goal: Maximize Return
The agent wants to maximize the Expected Cumulative Reward.
$$ G_t = r_{t+1} + \gamma r_{t+2} + \gamma^2 r_{t+3} + ... $$
$\gamma$ (Gamma) is the Discount Factor: Rewards now are better than rewards later.
Exploration vs Exploitation
The fundamental dilemma:
- Exploitation: Do what you know yields reward.
- Exploration: Try something random to see if there's a better payoff.
Epsilon-Greedy strategy: 10% of the time, act randomly.
Q-Learning
We want to learn a function $Q(s, a)$:
"How good is it to take action $a$ in state $s$?"
Deep Q-Networks (DQN)
For complex games (Atari, Doom), the state space is too big for a table.
Solution: Use a Neural Network to approximate the Q-function.
$$ \text{Input (Pixels)} \to \text{CNN} \to \text{Q-Values for actions} $$
Policy Gradients
Instead of learning Q-values, learn the Policy $\pi(s)$ directly.
- The network outputs a probability distribution over actions.
- If an action leads to a win, increase probability of that action.
Used in ChatGPT (RLHF - Reinforcement Learning from Human Feedback).
AlphaGo & AlphaZero
Combined:
- Monte Carlo Tree Search: Planning ahead.
- Deep RL: Evaluating board positions.
Result: Defeated world champions in Go, Chess, and Shogi.
Conclusion & Future
Current Challenges
- Compute Cost: Training huge models costs millions.
- Data Hunger: Running out of high-quality internet text.
- Explainability: "Black Box" problem remains.
- Bias & Safety: Models hallucinate and reflect training biases.
Summary
- CNNs: Still the standard for Vision.
- RNNs/LSTMs: Legacy approach.
- Transformers: Current SOTA with Attention.
- Diffusion: SOTA for image generation.
- RL: Decision making agents.